This page was generated from notebooks/0A-SwyftModule.ipynb.
SwyftModule¶
In this notebook, we will go through the basic steps of performing parameter inference with Swyft.
Setup¶
First we need some imports.
[1]:
%load_ext autoreload
%autoreload 2
[2]:
import numpy as np
import swyft
import pylab as plt
import scipy.stats
Training data¶
Now we generate training data. As simple example, we consider the model
where the parameter \(z \sim \mathcal{N}(\mu = 0, \sigma = 1)\) is standard normal distributed, and \(\epsilon \sim \mathcal{N}(\mu = 0, \sigma = 0.1)\) is a small noise contribution. We are interested in the posterior of \(z\) given a measurement of parameter \(x\).
[3]:
N = 10000 # Number of samples
z = np.random.rand(N, 1)*2-1 # Uniform prior over [-1, 1]
x = z + np.random.randn(N, 1)*0.1
Training data that is kept in memory is stored in a swyft.Samples object.
[4]:
samples = swyft.Samples(x = x, z = z)
Inference network¶
The inference network is an instance of swyft.SwyftModule. It estimates ratios of the form
where \(A\) and \(B\) refer to any subset of variables in the training data. In the below example, we set \(A \to x\) and \(B \to z\).
We use here a standard dense network, swyft.LogRatioEstimator_1dim, for mapping \(x\) and \(z\) onto a ratio estimator object.
[5]:
class Network(swyft.SwyftModule):
def __init__(self):
super().__init__()
self.logratios = swyft.LogRatioEstimator_1dim(num_features = 1, num_params = 1, varnames = 'z')
def forward(self, A, B):
logratios = self.logratios(A['x'], B['z'])
return logratios
Trainer¶
Training is now done using the SwyftTrainer class, which extends pytorch_lightning.Trainer by methods like infer (see below). Since our training data is double precision in this example, we have to set precision = 64.
[6]:
trainer = swyft.SwyftTrainer(accelerator = 'gpu', devices = 1, max_epochs = 10, precision = 64)
GPU available: True (cuda), used: True
TPU available: False, using: 0 TPU cores
IPU available: False, using: 0 IPUs
HPU available: False, using: 0 HPUs
The swyft.Samples class provides convenience functions to generate data loaders for training and validation data. We preserve 1000 samples for validation and testing. The setting of num_workers will depend on your system.
[7]:
dm = swyft.SwyftDataModule(samples, fractions = [0.8, 0.02, 0.1], num_workers = 3, batch_size = 128)
[8]:
network = Network()
Finally, we perform the fit. (Potential warning messages related to logging and checkpoints can be ignored at this point. Proper logging will be discussed in a later notebook.)
[9]:
trainer.fit(network, dm)
/home/weniger/miniconda3b/envs/zero/lib/python3.9/site-packages/pytorch_lightning/callbacks/model_checkpoint.py:616: UserWarning: Checkpoint directory /home/weniger/codes/swyft/notebooks/lightning_logs/version_10053910/checkpoints exists and is not empty.
rank_zero_warn(f"Checkpoint directory {dirpath} exists and is not empty.")
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0]
| Name | Type | Params
-----------------------------------------------------
0 | logratios | LogRatioEstimator_1dim | 17.4 K
-----------------------------------------------------
17.4 K Trainable params
0 Non-trainable params
17.4 K Total params
0.139 Total estimated model params size (MB)
`Trainer.fit` stopped: `max_epochs=10` reached.
Finally, we can test the network performance on the separate testing samples.
[10]:
trainer.test(network, dm)
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0]
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━┓ ┃ Test metric ┃ DataLoader 0 ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━┩ │ test_loss │ -0.8360220992058839 │ └───────────────────────────┴───────────────────────────┘
[10]:
[{'test_loss': -0.8360220992058839}]
Inference¶
We assume that we measure the values \(x=0.2\).
[11]:
x0 = 0.2
Below we will need that this is a Sample object.
[12]:
A = swyft.Sample(x = np.array([x0]))
We first generate a large number of prior samples.
[13]:
B = swyft.Samples(z = np.random.rand(1_000_000, 1)*2-1)
Swyft provides the method infer in order to efficiently evaluate the inference network. That method takes either dataloaders or individual samples (i.e. dictionaries of tensors) as input. This efficiently evaluates the ratio \(r(x; z)\) for a large number of prior samples \(z\) for a fixed values of \(x\).
[14]:
predictions = trainer.infer(network, A, B)
WARNING: Deprecated
WARNING: Deprecated
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0]
/home/weniger/miniconda3b/envs/zero/lib/python3.9/site-packages/pytorch_lightning/loops/epoch/prediction_epoch_loop.py:173: UserWarning: Lightning couldn't infer the indices fetched for your dataloader.
warning_cache.warn("Lightning couldn't infer the indices fetched for your dataloader.")
Plot results¶
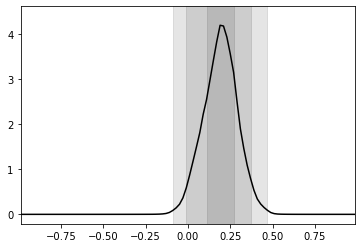
First we obtain samples from the posterior, using subsampling with a weight that happens to be given by \(e^r\).
[17]:
swyft.plot_1d(predictions, "z[0]", ax = plt.gca())
[ ]:
This page was generated from notebooks/0A-SwyftModule.ipynb.